Nice to meet you, I’m Jasper Drescher, and I am part of the Programming team at Synapse Studio.
This time I would like to help demystify common myths surrounding the performance of Blueprints in Unreal Engine 5 and explain how they work.
Blueprint Visual Scripting was introduced in Unreal Engine 4 and replaced the Kismet Visual Scripting language and UnrealScript. Unreal Engine 4 however was released in 2014, which is over a decade ago. Since then, Epic Games has made significant improvements to Blueprint Visual Scripting. While Blueprints are a convenient way to add logic and visuals to your Unreal Engine project, they are often associated with the term “overhead” when it comes to performance.
Why Blueprints incur overhead
Generally speaking, if we ignore the implementation of the desired functionality and architecture by a developer within an Unreal Engine project, there are four main aspects that introduce overhead:
Interpreted Execution
In short, Blueprints are compiled into custom bytecode and interpreted by a virtual machine (VM) at run-time, whereas C++ code is compiled directly into machine code and runs natively. This means that Blueprint scripts incur additional overhead from the VM’s interpretation process, leading to slower execution times. On top of that, a C++ compiler can optimize the code. For example, when generating assembly, the compiler can avoid unnecessarily copying a variable when passing it to a function. For Blueprints the C++ compiler can only optimize the native functions that are called internally by the nodes. The process of writing, compiling and execution is therefore comparable to running Java versus C++ code.
Function Call Overhead
Each Blueprint function call involves setting up parameters and invoking virtual functions to bind the Blueprint nodes and properties to C++ functions within the engine, which can be costly in terms of performance. This overhead is particularly noticeable when functions are called frequently or with large amounts of data to process.
Single-Threaded Execution
Blueprints execute on a single thread, limiting their ability to leverage multiple cores to execute code in parallel. This can lead to performance bottlenecks, especially in complex or resource-intensive scenarios.
Garbage Collection
Blueprints have a mark-and-sweep garbage collector to manage memory. The engine tracks hard-referenced UObjects, either directly or indirectly, through the root set. When a UObject becomes unreferenced, it is marked as unreachable and will be destroyed during the next garbage collection cycle. The reachability analysis of the references and destruction of UObjects can negatively impact performance. A mark-and-sweep analysis, where unreferenced UObjects are marked for destruction, can look like this:
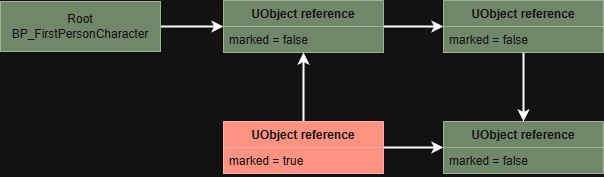
Performance deep dive
The Virtual Machine
To understand more about the Blueprint Virtual Machine and the bytecode that it interpretes at run-time, we can compare two implementations of a LineTraceByChannel on BeginPlay in Unreal Engine 5.
Here is the implementation in Blueprint:
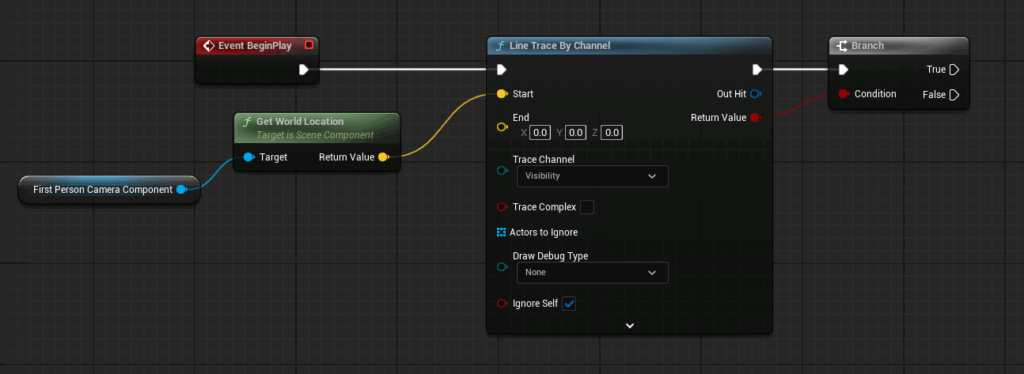
And here is the implementation in C++:

When we enable the debugging of the intermediate representations for both, we get the following for the Blueprint:
LogK2Compiler: [function ExecuteUbergraph_BP_FirstPersonCharacter]:
...
Label_0x3D:
$14: LetBool (Variable = Expression)
Variable:
$0: Local variable of type bool named CallFunc_LineTraceSingle_ReturnValue.
Expression:
$68: Call Math (stack node KismetSystemLibrary::LineTraceSingle)
$17: EX_Self
$0: Local variable of type FVector named CallFunc_K2_GetComponentLocation_ReturnValue.
$23: literal vector (0.000000,0.000000,0.000000)
$24: literal byte 0
$28: EX_False
$0: Local variable of type TArray<AActor*> named Temp_object_Variable. Parameter flags: (Reference,Const).
$24: literal byte 0
$0: Local variable of type FHitResult named CallFunc_LineTraceSingle_OutHit.
$27: EX_True
$2F: literal struct LinearColor (serialized size: 16)
$1E: literal float 1.000000
$1E: literal float 0.000000
$1E: literal float 0.000000
$1E: literal float 1.000000
$30: EX_EndStructConst
$2F: literal struct LinearColor (serialized size: 16)
$1E: literal float 0.000000
$1E: literal float 1.000000
$1E: literal float 0.000000
$1E: literal float 1.000000
$30: EX_EndStructConst
$1E: literal float 5.000000
$16: EX_EndFunctionParms
...
Label_0xD8:
$7: Jump to offset 0xF3 if not expr:
$0: Local variable of type bool named CallFunc_LineTraceSingle_ReturnValue.
...Although Blueprint Nativization is not possible in Unreal Engine 5, we can visualize the machinecode that is similar to the implementations above back in Unreal Engine 4:

On the left we can see the machinecode with assembly instructions for C++ and on the right the Blueprint implementation with bytecode. Both implementations are turned into a one-dimensional set of instructions. On the left, the instructions for the CPU that are optimized by the compiler. On the right, the instructions and labels are for the Blueprint VM to interpret. This additional layer between the nodes in the event graph and the CPU is what we refer to as overhead.
Tick Events
Did you know that Event Tick nodes in the event graph can still execute if they have no other nodes attached to the execution impulse? Empty ticks actually still execute for each actor, which takes about 0.1 microseconds per frame. Ghost tick functions do not execute at all just like when the node is removed.
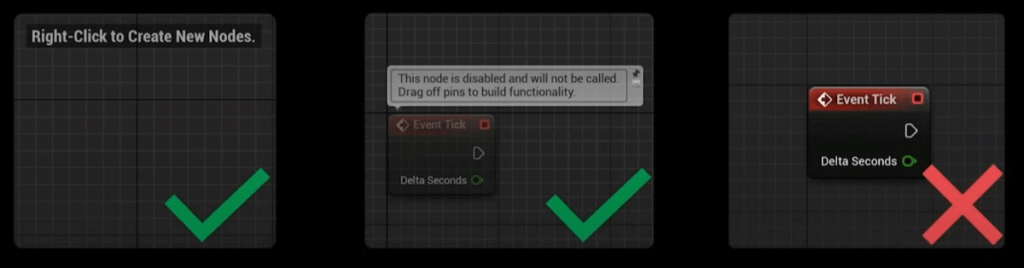
By profiling the Event Tick node and ReceiveTick from UWorld in C++ in the First Person Character template, we can gather performance data. The following data has been captured by running the FP template in Unreal Engine 5.5.4 as a separate process from the editor. The hardware specifications for this test are a PC with an AMD Ryzen 7 5700X 8-Core CPU @ 3.40 GHz and 16GB DDR4 RAM @ 3600 Mhz. When we spawn 100 Blueprint Actors and 100 C++ Actors we get the following results:
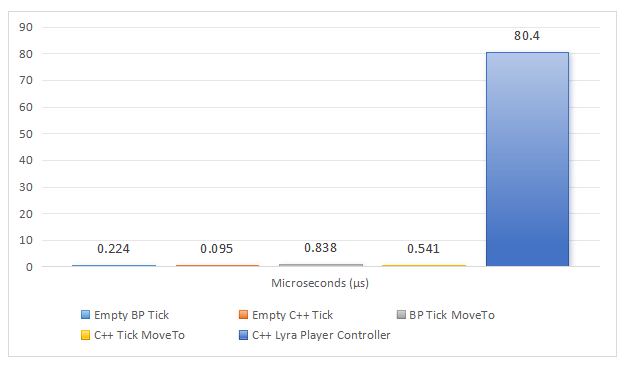
We can see that each actor with an empty Event Tick takes up about 0.2 microseconds if it’s a Blueprint and 0.1 microseconds if it’s a C++ class. For the implementation of the Simple Move To that runs on Event Tick we can see a small increase of execution time per frame. It would take 500 actors with this implementation in the current level to reach 1 millisecond, or 1/16 (0.06%) of your frame budget on the CPU if you aim for 60 FPS. For comparison, the C++ implementation of the Player Controller in the Lyra Example Game takes up 80.4 microseconds per frame to process player input and movement.
This is the implementation of the Simple Move to Actor on Tick in Blueprint:

And this is the custom implementation of the Simple Move to Actor on Tick in C++, as there is no equivalent function from the engine:
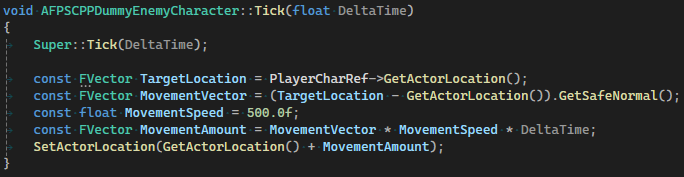
What matters the most with Tick events is also the amount of logic done in the event rather than using the Tick event itself.
Myths
Avoid using Cast
The first myth that comes to mind is that casting in Blueprints should be avoided as much as possible, but this is not necessarily true. To understand why, we can look at different cases where you may consider casting.
The reason why casting can impact performance is because casting to a Blueprint type also references it, which adds them as a dependency and are always loaded before the root Blueprint and stay loaded while they are referenced.
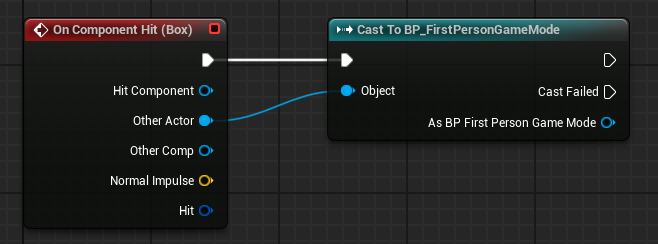
A cast like above can be necessary to access a function from the Blueprint or C++ class of a specific type. Doing this is not bad practice as long as you keep in mind that you should only hold relevant hard references and cast when there is no other option.
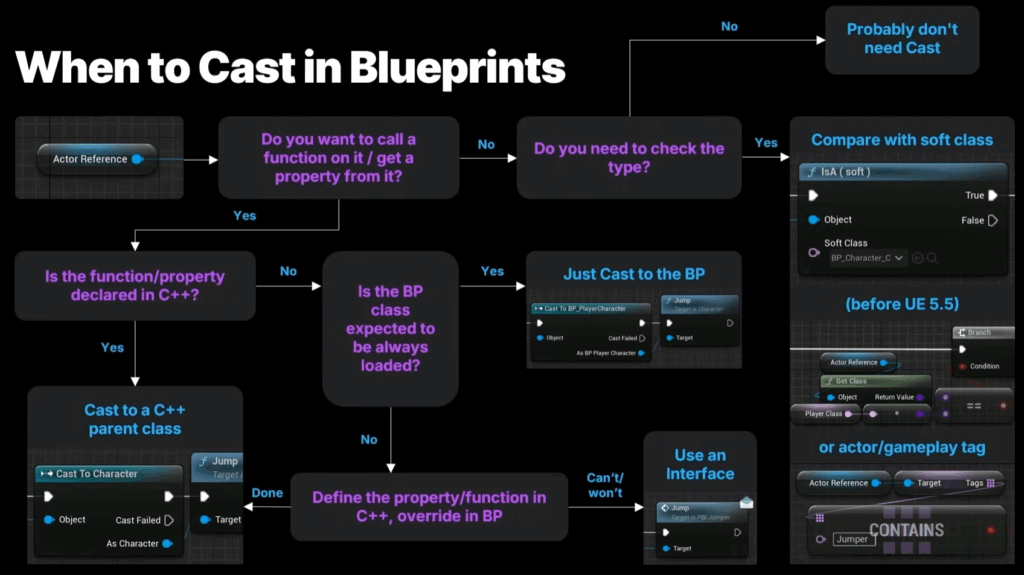
This is the flowchart provided by Epic Games that explains when to use casting:
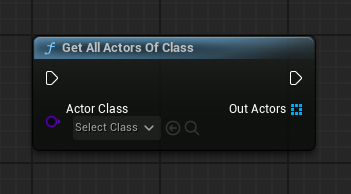
Avoid using GetAllActorsOfClass
The second common myth is that GetAllActorsOfClass is a complex function that should be avoided at all costs, but the function might be less costly than you think. First of all, the function itself is used throughout the engine and called multiple times per frame in Unreal Engine 5, so it already has its use case. Secondly, just like any iterator, the execution time scales with the amount of actors it gets. As long as you know that the amount of actors you expect to get of the class that is put in, it can be fine to iterate over them and perform a limited set of logic each iteration. GetAllActorsOfClass used to iterate over every actor in the current level, but since 2013 it uses hash buckets to drastically improve performance. However GetAllActorsWithInterface and GetAllActorsWithTag still loop over every actor in a map and are therefore slower.
As long as you use GetAllActorsOfClass and keep the amount of operations done for each actor in the loop low and with a low amount of actors to find it will only take a few microseconds. The impact on each frame will therefore be low. If you aim for 16.67ms, or 60 FPS, then it won’t even take 1% of performance budget per frame.
Avoid using ChildActorComponent
Another myth that I come across often is that ChildActorComponent is a dangerous component and it should be avoided. Especially for developers who are used to working in Unity, the ChildActorComponent can be useful as a replacement for prefabs. Having nesting or complex logic beyond just VFX on the component can make it unstable however. It does not incur a significant overhead compared to regular actor components, so it is safe to use as long as the logic is limited and any references are accessed correctly within the ChildActor.
Avoid using Tick
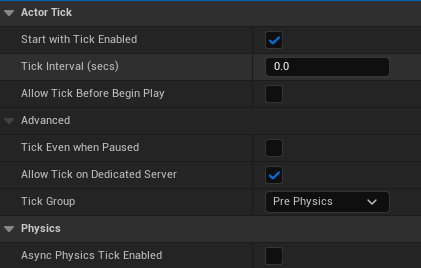
The last myth that I can think of that is quite common, is that you should not execute anything on Event Tick. On one hand it is understandable that putting logic in the event graph on Event Tick, or when a tick is received from UWorld in the engine, as you can see an immediate impact on the performance of your game. The tick event executes every frame if your actor has set PrimaryActorTick.bCanEverTick to true, or “Start with Tick” enabled and “Tick Interval” to 0.0. If you search for “Tick” in the Class Defaults of your Blueprint, then you’ll find several settings that you can modify to improve performance based on the usage of your Blueprint. For example, reducing the Tick Interval or disabling the Tick will improve performance.
When it comes to scripting in the event graph, it is fine to run logic in Event Tick. The only thing that you have to keep in mind is that the more logic you perform in your Blueprint when a Tick is received, the more it will impact performance. It’s therefore useful to move some logic to C++ if it involves a lot of mathematics or data so that it can be optimized by hand and by the compiler. If you are unsure how much your Blueprint impacts your Event Tick, then you can always analyze your project with Unreal Insights.
Blueprint Optimization
Blueprint and object lifetimes
A useful thing to consider when scripting Blueprints and adding references is that different Blueprint classes have different lifetimes themselves. The Level Blueprint and Game Mode Blueprint are tied to the current level and will reset when the level changes. Blueprint Actors and Child Actors will be destroyed when they are unreferenced in the current level or when the level is reset. The Game Instance Class exists throughout the entire game session. It’s therefore good to put the data in the Blueprint with the appropriate lifetime. For example, if you need to store global data about the current game or online players, storing it in the Game Instance Class would be ideal. This can also be used to avoid duplicating data in multiple Blueprints. However, if you store a lot of data in that class, it won’t be destroyed to free up memory due to its lifetime.
Garbage Collection
In Unreal Engine 5, you can greatly reduce any impact of garbage collection cycles by keeping a few things in mind. You can also enable the experimental Incremental Garbage Collection, which spreads out the reachability analysis across multiple frames. You can enable the incremental garbage collection by modifying the DefaultEngine.ini in your project:
[ConsoleVariables]
gc.AllowIncrementalReachability=1 ; enables Incremental Reachability Analysis
gc.AllowIncrementalGather=1 ; enables Incremental Gather Unreachable Objects
gc.IncrementalReachabilityTimeLimit=0.002 ; sets the soft time limit to 2msYou can find more about the experimental feature here: Incremental Garbage Collection in Unreal Engine. Besides that, there are also a less experimental project settings and design approaches to improve performance.
We can see an example of the impact of the garbage collector on performance in comparison in Unreal Insights:
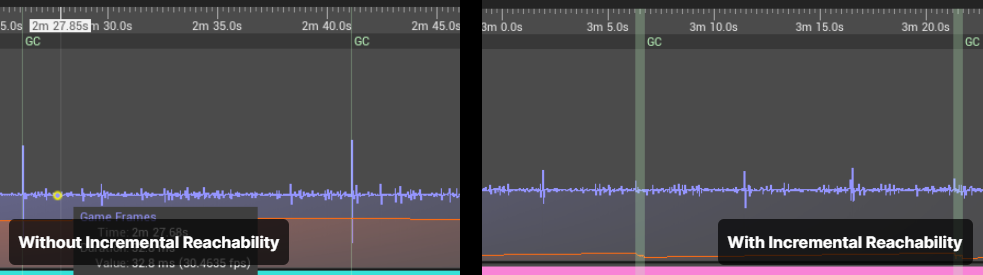
On the right, with incremental reachability turned on, you can see that the lag spikes are gone, and that incremental reachability is now split across multiple frames as shown by the green lines.
In Unreal Engine 5, you can enable parallel garbage collection in order to run that on multiple threads, you can enable the incremental destruction of objects per frame to spread them out, you can modify the asset and garbage collection clusters, etc. You can find more settings here: Garbage Collection in Unreal Engine Settings
Developers can prevent unnecessary garbage collection by creating hard-references to UObjects. Two examples of doing so are:
- Holding a reference to a UObject in an instance of a blueprint class or UPROPERTY in C++
- Adding an instance of a UObject to a root set in C++
Remarks
Blueprint Nativization
Blueprint Nativization has been removed in Unreal Engine 5. This means that it is harder to convert more of your logic into C++ code and improve run-time performance. However, the C++ Header Preview can still be somewhat helpful to visualize a Blueprint Class in C++ to convert some variables.
Kismet
The Blueprint Visual Scripting Language replaces the UnrealScript and Kismet Visual Scripting from Unreal Engine 3. Back then, the visual scripting language was called Kismet, which is why a lot of engine configuration variables and C++ classes still use this name.
Bytecode
If you want to see a human-readable version of the custom bytecode of Blueprints, then you can set these variables in the BaseEngine.ini in your UE5 installation folder:
[Kismet]
AllowDerivedBlueprints=true
CompileDisplaysTextBackend=true
CompileDisplaysBinaryBackend=trueYou can also add it to your DefaultEngine.ini for your project, but they don’t exist there by default. The intermediate bytecode will appear in the Output Log after compiling a Blueprint.
Conclusion
After some mythbusting we now understand how Blueprint scripts impact performance. We’ve discussed several approaches to keep the impact on performance low as well. The general philosophy is that you can use Blueprints to their fullest extend, as long as you keep the lifetimes of Blueprints and references in mind and keep the logic that has to be executed every Tick low. Whenever performance is a concern, Unreal Insights can be used to profile which Blueprints and functions are taking up a lot of execution time and impacting performance.